Oct 27, 2025
Why Enterprise Search is still broken and how OneSearch unlocks true Enterprise Intelligence

Written by Shiraz Zaman | Founder & CEO, Nand AI
Here’s a stat that should keep every CEO up at night: knowledge workers spend about 20% of their time, roughly one full day every week, searching for information they need to do their jobs.
That’s $5 trillion in lost productivity every year across global enterprises.
Nand AI started with a simple realization: Accuracy isn’t just a feature; it’s the foundation of any production-grade AI system. Today, I want to show you what that foundation unlocks: a completely new way to find and reason over enterprise knowledge - something traditional search never could.
After building AI systems at scale for Lyft and Microsoft, I initially believed enterprise search was a solved problem until real customer conversations proved otherwise. When I started talking to sales teams, I realized something uncomfortable: for the past twenty years, companies have been solving the wrong problem.
Let me show you what I mean. Ask any sales rep these questions:
What exactly did we promise Acme Corp in their Q2 contract about data residency?
Show me every conversation where customers asked about our SOC 2 compliance in the last six months.
What competitive intelligence do we have on the three deals we lost to Competitor X this quarter?
With existing enterprise search tools, whether they come from big-tech incumbents or the latest AI-powered startups, you’ll get one of three responses:
Too many irrelevant results, for example, 400 documents mentioning “Acme Corp.”
Not enough relevant results, missing the key Slack thread where this was actually discussed.
Confidently wrong answers, hallucinating a policy that doesn’t exist.
Sound familiar? You’re not alone. This is what we heard through more than one hundred customer interviews. This isn’t a training problem or a user-adoption problem. It’s an architecture problem that continues to impact enterprise knowledge management.
Why AI Enterprise Search Still Fails
I have enormous respect for the companies building AI enabled enterprise search. They’ve pushed the industry forward. But after analyzing why our customers were dissatisfied with these tools, we identified three critical architectural failures that no amount of fine-tuning can fix.
1. The Haystack Problem: They Can’t Filter Noise
Standard AI enterprise search uses vector embeddings to find “similar” content. That sounds intelligent, right? Except “similar” is not the same as “relevant.”
When you search for “Acme Corp data residency,” traditional tools will return:
✅ The actual Acme contract (relevant)
❌ Forty-seven other customer contracts mentioning data residency (noise)
❌ An old proposal draft from 2022 (outdated)
❌ An internal discussion about a different Acme Corp (wrong entity)
❌ A blog post about data residency best practices (irrelevant context)
This is what happens when search systems optimize for similarity, not relevance. You’re left sifting through hundreds of results, and the user ends up spending more time filtering noise than they would have spent asking a colleague.
The fundamental problem is that these systems retrieve everything that might be relevant and dump it into the language model, hoping it can sort through the mess. It cannot. These noise-filled results also reflect broken enterprise data integration practices.
2. The Recency Blindness: They Don’t Know What’s Current
I learned this lesson the hard way at Microsoft. Date stamps can be misleading.
A document that was modified yesterday might only have a typo fix. Meanwhile, the actual current policy could be from six months ago but hasn’t needed updates. Standard AI search cannot tell the difference.
Even worse, these tools cannot understand implicit freshness signals such as:
This contract superseded the previous one.
This Slack thread reflects the latest status update, even if the original project document is older.
This email cancels the meeting notes from last week.
When your sales rep gets outdated pricing from a search tool and quotes it to a customer, that is not a small problem. That is a lost deal and a damaged relationship. This issue also shows how enterprise knowledge management often fails when freshness and accuracy are not prioritized.
3. The Synthesis Gap: They Can’t Connect the Dots
Here is where things break completely. Try asking: “Across our top 10 lost deals this quarter, what were the three most common objections, and how did our competitors position against us?”
Traditional search, even AI-powered, will fail because it cannot:
Identify which deals were “top” (requires CRM context)
Understand what constitutes an “objection” (requires semantic understanding)
Synthesize patterns across multiple conversations
Extract competitive intelligence from unstructured notes
Connect deal outcomes to specific objection themes
This is not a search. This is intelligence. And it requires a completely different architecture. The inability to connect insights highlights why enterprise knowledge management requires contextual reasoning.
Introducing OneSearch: What Accuracy Unlocks
Earlier this year, we introduced Magus, our evaluation-oriented retrieval engine that achieves up to 90% recall and 95% accuracy on benchmarked enterprise RFP responses. Nine out of ten GenAI pilots fail because of inaccuracy. We solved that problem by building validation directly into the architecture.
What I didn’t mention is that once you solve accuracy, you unlock something far bigger than better RFP responses. You unlock the ability to trust your AI to find truth in chaos, to synthesize intelligence from fragments, and to answer questions that require reasoning across your entire enterprise knowledge base.
That is what we have built with OneSearch, not enterprise search, but enterprise understanding powered by the same Magus foundation that our customers describe as “consistently hitting the mark and often outperforming expert responses.”
How It Works: Three Layers of Intelligence
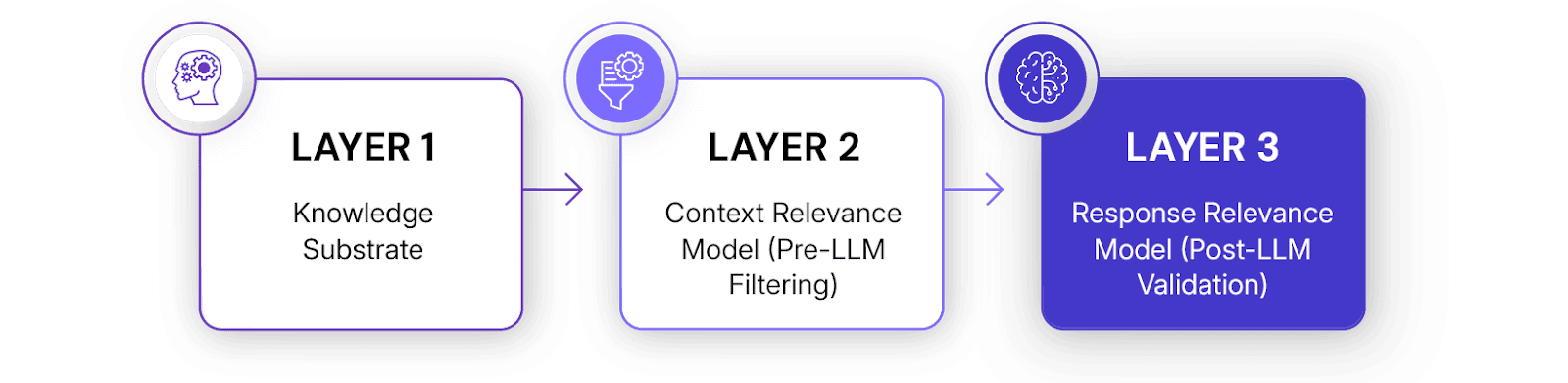
Layer 1: Knowledge Substrate
Traditional search treats your documents as isolated islands. OneSearch builds a knowledge graph that understands:
Entity relationships: This Acme Corp is the $2 million per year customer, not the prospect with the same name.
Document hierarchy: This contract supersedes the old proposal.
Temporal context: This Slack thread discusses the current state, even if the original document is older.
Cross-reference chains: These six documents all relate to the same customer issue.
This is why OneSearch outperforms retrieval-based systems by 6x - because it doesn’t just 'retrieve', it understands. We are not guessing what is relevant; we know. This structure also improves enterprise data integration and relevance understanding.
Layer 2: Context Relevance Model (Pre-LLM Filtering)
Before the language model sees anything, this layer filters your enterprise knowledge. It does not retrieve “similar” documents. It identifies precisely what matters for the specific question.
Standard RAG systems feed roughly 85% irrelevant content into the LLM. This layer eliminates that problem completely. The AI never even sees the noise. It also enhances enterprise knowledge management by filtering data before reasoning occurs.
Layer 3: Response Relevance Model (Post-LLM Validation)
After the LLM generates an answer, this validator checks it against the source material. It catches hallucinations, spots inconsistencies, and flags incomplete responses before they reach your team.
The architecture, validation, and accuracy foundation remain the same. The result is straightforward: when OneSearch returns five results, all five are relevant, not five out of fifty.
Real-World Impact: From Hours to Seconds
Let me show you what this looks like in practice. One of our early customers, a cybersecurity company, had a sales representative who spent three hours researching competitive intelligence before an important customer call. They searched through past deal notes in Salesforce, Slack conversations with the product team, competitor analysis documents scattered across Google Drive, and email threads with customers who had evaluated both solutions.
After deploying OneSearch, that same research query took:
Query time: 12 seconds
Results returned: 8 highly relevant documents
Synthesis generated: a complete competitive positioning brief with citations
Time saved: 2 hours and 59 minutes
When you multiply that across every sales call, every RFP, and every customer question, the productivity gains compound exponentially.
But here is the part that matters more. They trust the answers. They do not spend 30 minutes double-checking every result. They see the citations, verify the sources, and move forward with confidence. That is what accuracy unlocks. This shows how an intelligence layer like OneSearch can directly improve efficiency and decision-making.
Why This Wasn’t Possible Before
You might be wondering: if this is so obvious, why hasn’t someone built it already? There are three reasons, and each took years to solve.
1. Data Engineering Is Brutally Hard
Building a knowledge substrate that works seamlessly across Salesforce, Google Drive, Slack, email, and custom databases, while maintaining data security, privacy, and complete tenant isolation, is a multi-year engineering challenge. Effective enterprise data integration is essential here. Most search companies focus on the retrieval layer and hope the data will somehow organize itself. It does not.
2. Evaluation Requires Domain Expertise
Our context and response relevance models are not generic. They are bootstrapped with tens of thousands of real-world public data points, trained on enterprise sales workflows, continuously refined through real usage, and tuned to understand business context.
This requires deep experience building production AI systems. My team spent years at Lyft, Microsoft, and Salesforce developing machine learning systems that served millions of users every day. We learned what breaks at scale, and we built OneSearch to avoid those failures entirely.
3. The Accuracy Bar Is Higher Than It Looks
Reaching 70% accuracy is easy. Every AI demo can hit 70%. Achieving 90% recall and 95% accuracy, while also maintaining 82% comprehensiveness (these are stats achieved by Nand AI Magus), requires solving dozens of edge cases that only surface at production scale.
We have processed millions of queries to get here. Every edge case taught us something. Every failure made the system stronger.
The Future of Enterprise Knowledge Management
Here is my controversial take: enterprise search as a standalone product is dead. What enterprises actually need is an intelligence layer that sits across all their systems and answers questions such as:
What is the status of the Johnson deal? (synthesizes CRM, email, and calendar data)
Why did we lose to Competitor X? (analyzes deal history and identifies patterns)
What did we promise this customer? (connects contracts, calls, and emails)
This is much more than search. It is enterprise knowledge management combined with reasoning and synthesis.
That is what OneSearch is becoming. In a world where every company has access to the same language models, your competitive advantage will come from how well you can contextualize those models with your own enterprise knowledge.
OneSearch isn’t the next generation of enterprise search - it’s the first generation of enterprise intelligence.
Context is the new moat, and accuracy is how you defend it.
Experience It Yourself
We are opening OneSearch to a limited number of early access partners. If your team is drowning in information but starving for answers, let’s talk.
What you’ll get:
A pilot with your actual data
Direct access to our engineering team
No credit card required for the pilot
What we’re looking for:
B2B companies with more than 100 employees
Complex sales cycles or customer interactions
Teams willing to provide feedback and iterate with us
If your organization struggles with fragmented data and inconsistent search results, this is an opportunity to experience how accuracy can truly transform productivity.
Sign-up for early access | Read more about OneSearch on our website
Shiraz Zaman is the CEO and Co-Founder of Nand AI. He previously led AI initiatives at Lyft, where he built AI Systems powering every Lyft ride, and was a Senior Scientist at Microsoft Bing Ads, where he developed AI models to improve relevance. He holds a bachelors degree in Computer Science from IIT Delhi.
Ready to craft business responses in minutes?
Book a personalized demo and see how Nand AI fits into your workflow.



© Copyright 2025. All Rights Reserved by Nand AI