Platform
The Foundational Context Engine for Enterprise AI
Nand AI reconstructs complete meaning across your enterprise so AI systems reason correctly and execute reliably.
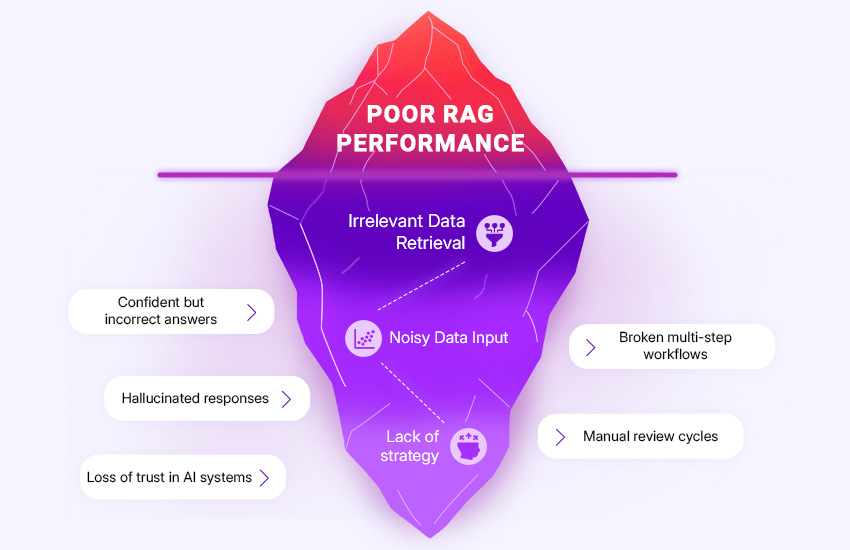
Why Enterprise AI Fails
Most enterprise AI systems rely on standard Retrieval-Augmented Generation. These pipelines retrieve partial information and ask the model to infer the rest.
~ 20%
AVERAGE RELEVANT CONTEXT RETRIEVAL
The Core Problem: Fragmented Context
Context First. Reasoning Second.
Nand AI doesn’t pass fragments to a model. It reconstructs full meaning before any reasoning begins.
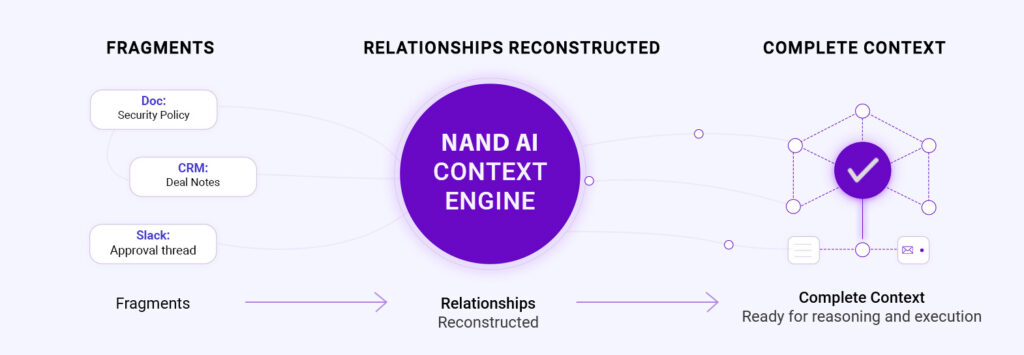
We connect documents, conversations, systems, and timelines into a single, living context graph.
So AI reasons over relationships, not isolated text.
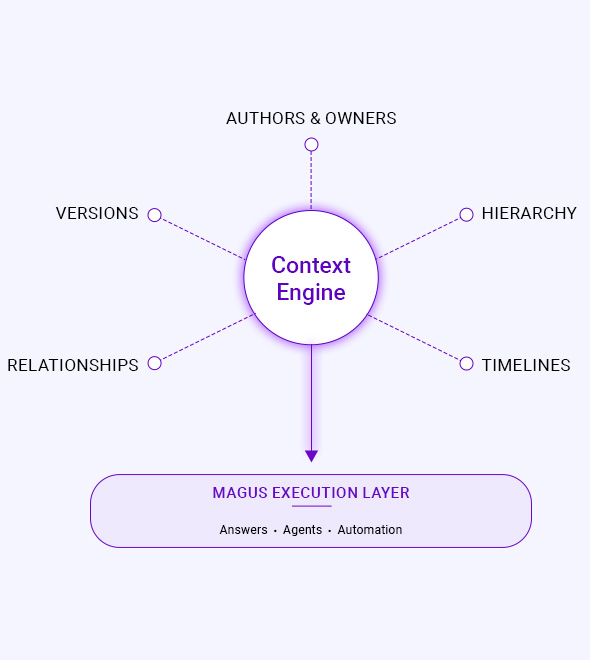
Context Engine
Platform Architecture Overview
At the core of the platform is the Nand AI Context Engine.
It models enterprise knowledge as a continuously evolving graph that preserves:
- Authorship and ownership
- Section hierarchy and versions
- Timelines and dependencies
- Cross-system relationships
- Additional entities that define your enterprise paradigm
This graph becomes the system of record for meaning across the enterprise.
EXECUTION LAYER
Powered by this engine, Magus is the execution layer that delivers answers, agents, and automation across enterprise workflows.
Core Capabilities
Turning fragmented enterprise data into coherent, actionable intelligence.
The Context Pipeline
Reconstructing enterprise knowledge as a connected system, not an index. Each stage increases recall, reduces hallucinations, and improves agent reliability.
01
Ingest
Connect documents, chats, tickets, and internal tools.
02
Discover
Automatically map complex relationships and hierarchies.
03
Build
Construct a evolving Enterprise Knowledge Graph.
04
Validate
Score context quality and audit every source accurately.
05
Power
Drive agentic workflows with reliable, complete context.
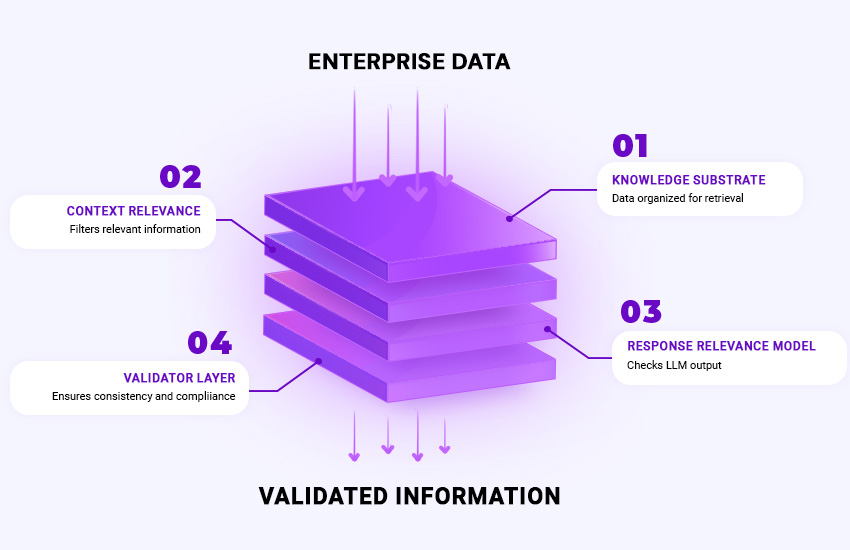
Built-In Validation Layer
Nand AI includes a mandatory validation layer.
- Pre-generation filtering ensures only trusted context reaches the model
- Post-generation validation checks outputs against source material
- Confidence scoring surfaces uncertainty
This removes black-box behavior and enforces deterministic grounding.
Context recall
Hallucination rate
Multi-step workflow success
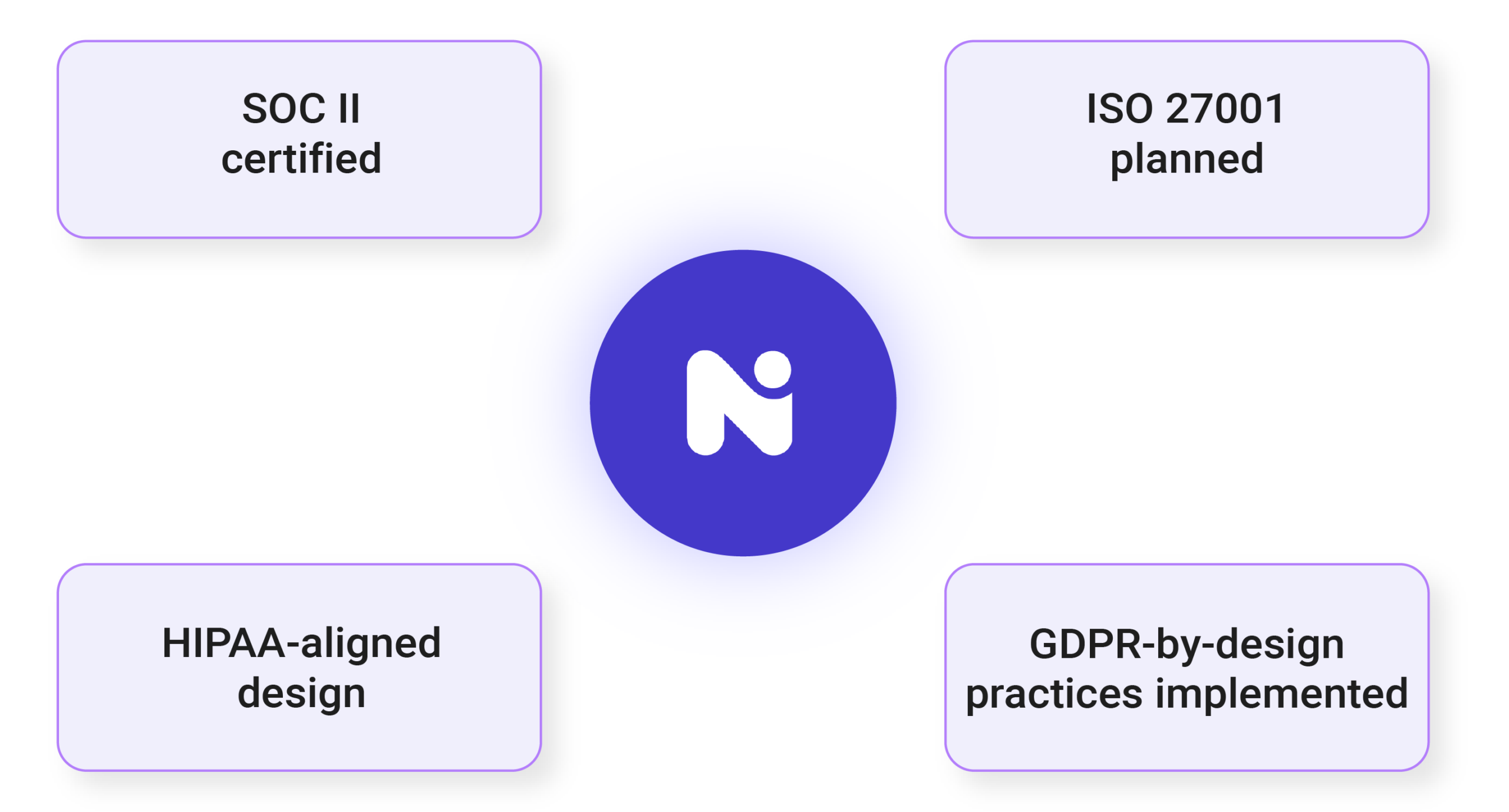
Enterprise Security Architecture
Nand AI is architected for enterprise security and compliance.
- Tenant-isolated architecture
- Zero training on customer data
- Encrypted pipelines
- Fine-grained access controls
- Full audit trails
Your data remains under your control.
Integrations Layer
Built for Real Enterprise Systems
Direct integration that inherits your existing permissions and access controls.
No shadow access. No duplicated data. No security gaps.
01.
Permission-Aware by Design
-
Enforces role-based access control
-
Users only see what they’re authorised to access
-
Team and object-level restrictions are maintained
02.
Deep Enterprise Integration
-
Supports custom objects & schemes
-
Maps to your unique workflows
-
Integrates with your business logic
03.
Supported Systems
Salesforce, ServiceNow, SharePoint, Microsoft Teams, Slack, Google Drive, OneDrive, HubSpot, Confluence, Jira, Zendesk, Notion, and custom enterprise systems.
04.
No Disruption. No Rework.
-
No migration.
-
No data duplication.
-
No workflow changes.
Nand AI fits into your stack without forcing architectural compromise.
Onboarding
Enterprise-Ready Deployment Model
Production-ready in days, not months without disrupting existing systems.
Help Center
Frequently asked questions
Quick answers to questions you may have. Can't find what you're looking for? Reach us out
Magus is the execution layer powered by the Nand AI Context Engine. It securely connects to your trusted enterprise systems such as Google Drive, Salesforce, Slack, and ServiceNow, reconstructs full context across documents, authors, and timelines, and generates accurate, evidence-backed responses for workflows like RFPs, security questionnaires, and real-time sales support.
Magus is built for enterprise sales, pre-sales, proposal, legal, and procurement teams operating in complex, high-stakes environments. It is used by teams that require accurate, traceable answers across large and evolving knowledge bases. The Universal Search capability can be used across the organization to retrieve precise, context-aware answers.
Most customers are production-ready in hours, not weeks. Initial deployment is typically completed the same day, depending on the number of systems being connected.
General-purpose AI is designed for broad knowledge and open-ended conversation. It is not built for enterprise accuracy, governance, or traceability.
Magus is different in three critical ways:
- It operates only on your verified enterprise data
- Every answer is grounded with source citations
- Each response is confidence-scored to surface uncertainty
This makes Magus suitable for high-stakes enterprise workflows where correctness matters.
Accuracy is enforced through the Nand AI Context Engine and validation layer.
Every response is:
- derived from your verified source material
- checked against the knowledge graph for consistency
- rejected if it cannot be traced to a specific source or timestamp
This eliminates black-box behavior and ensures outputs are auditable.
Security is foundational to the Nand AI platform.
- All data is encrypted in transit and at rest
- Customer data is tenant-isolated
- Your data is never used to train third-party models
- Full audit trails are maintained for all access and activity
Nand AI is built for enterprise-grade security and compliance from the ground up.
Magus integrates with the systems where your enterprise knowledge already lives, including:
Google Drive, Salesforce, ServiceNow, Microsoft Teams, HubSpot, OneDrive, Jira, Zendesk, Slack, Notion, Confluence, and custom enterprise systems.
New connectors can be added without disrupting existing workflows.
Let’s Talk About Your Context Challenge
Tell us a bit about your environment, and we’ll show you how Nand AI reconstructs context for your specific workflows.